What is a DAG?
Airflow refers to what we've been calling "pipelines" as DAGs (directed acyclic graphs). In computer science, a directed acyclic graph simply means a workflow which only flows in a single direction. Each "step" in the workflow (an edge) is reached via the previous step in the workflow until we reach the beginning. The connection of edges is called a vertex.
If this remains unclear, consider how nodes in a tree data structure relate to one another. Every node has a "parent" node, which of course means that a child node cannot be its parents' parent. That's it - there's no need for fancy language here.
Edges in a DAG can have numerous "child" edges. Interestingly, a "child" edge can also have multiple parents (this is where our tree analogy fails us). Here's an example:
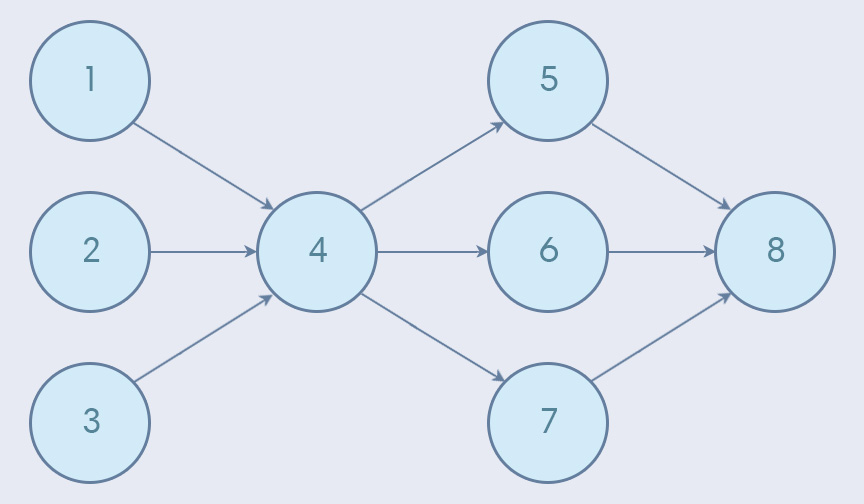
In the above example, the DAG begins with edges 1, 2 and 3 kicking things off. At various points in the pipeline, information is consolidated or broken out. Eventually, the DAG ends with edge 8.
Comments
Post a Comment